深入解析AI Gateway:AI 时代的流量管控核心
背景:AI Gateway 兴起
过去几年,大语言模型(LLM)与生成式 AI 技术飞速发展,推动各行业将 AI 能力大规模融入应用。这一趋势带来了激增的 AI API 流量,以及全新的管理与治理挑战。
在企业实践中,越来越多的组织采用混合云 AI 架构:既调用 OpenAI 等云端大模型服务,又在本地集群部署开源 LLM。这种模式虽然提升了灵活性,但同时引入了数据安全、成本管控、多模型编排、性能与可靠性等复杂问题。传统 API Gateway 面对这些 AI 特有场景显得力不从心,亟需演进。
在这种背景下,“AI Gateway”的概念逐渐成型。它不仅是 API 网关的自然延伸,更是针对大模型调用特性而生的全新基础设施。自 2023 年下半年以来,业界密集推出 AI Gateway 项目与产品:Envoy、Apache APISIX、Kong、Higress 等厂商相继行动,将网关能力与 AI 场景深度结合,目标是简化模型接入、强化安全治理、提升性能并降低成本。
总体来看,AI Gateway 的兴起,标志着 API 基础设施正迎来一轮面向 AI 场景的系统性升级。它既是技术演进的结果,也是产业加速拥抱 AI 的必然选择。
AI Gateway 与传统 API Gateway 的区别
表面看,大模型调用与普通 API 请求流程相近:客户端发起请求,网关转发至后端服务。然而,LLM 流量具备一系列与传统 API 截然不同的特性,使得既有网关难以直接满足需求。
| 维度 | 传统 API Gateway | AI Gateway |
|---|---|---|
| 计量与限流 | 按请求次数限流,粒度较粗 | 基于 Token 用量进行计量与限流,更精细地控制 LLM 成本 |
| 请求/响应可控性 | 主要检查请求参数,很少深度检查响应 | 内置请求/响应双向内容审核,拦截敏感输入/输出,保证合规 |
| 后端路由能力 | 面向固定后端,策略有限 | 智能流量调度,可在多模型间动态选择/切换 |
| 实时性与成本优化 | 关注可用性,对调用成本无感知 | 延迟/费用感知路由,动态负载均衡与弹性伸缩 |
| 并发与性能 | 优化短连接,对长连接与流式支持有限 | 面向流式输出优化,支持海量长连接与逐 Token 推送,基于高性能代理内核实现异步 I/O 与高并发调度 |
| 上下文与状态管理 | 偏无状态,对上下文维护有限 | 内置会话缓存、KV Cache 亲和、向量数据库集成,支持对话记忆与上下文管理 |
总体而言,AI Gateway 并非 API Gateway 的小步升级,而是围绕大模型服务的成本敏感性、内容安全性、异构路由需求与高并发挑战进行了深度重构。它既是 AI 流量的“高速公路收费站”,又是“安全检查口”和“调度中枢”。在企业级 AI 应用落地中,正逐步成为控制成本、保障合规、提升体验的核心基础设施。
市面主要 AI Gateway 产品概览
为提升可维护性,本文仅保留代表性项目(按字母序),每项包含一句定位与 1–2 个亮点;完整矩阵请参见原文链接:https://jimmysong.io/blog/ai-gateway-in-depth/
- Apache APISIX AI Gateway:
- 定位:基于 APISIX 插件体系扩展的 AI 流量能力;
- 亮点:ai-proxy 插件、多模型路由与自动重试回退、Token 桶限流与内容审核,统一治理 API 与 AI 流量。
- Cloudflare AI Gateway:
- 定位:托管化的 AI 流量观测与优化服务;
- 亮点:请求分析、缓存与速率限制、成本/延迟可视化,零运维集成现有调用。
- Envoy AI Gateway:
- 定位:面向服务网格/网关生态的原生 AI Gateway;
- 亮点:基于 Envoy/Envoy Gateway 扩展,支持 LLM 过滤器、Token 级用量限流与统一入口,多云多模型接入。
- Kong AI Gateway:
- 定位:Kong Gateway 的 AI 能力扩展;
- 亮点:请求/响应转换与提示模板、凭据集中管理、语义缓存与负载路由,便于现有网关一体化管理。
- OpenRouter:
- 定位:多模型统一 API 的聚合代理;
- 亮点:单一 API Key 调用多家模型、OpenAI API 兼容、自动路由/回退,降低应用改造成本。
AI Gateway 应具备的核心能力
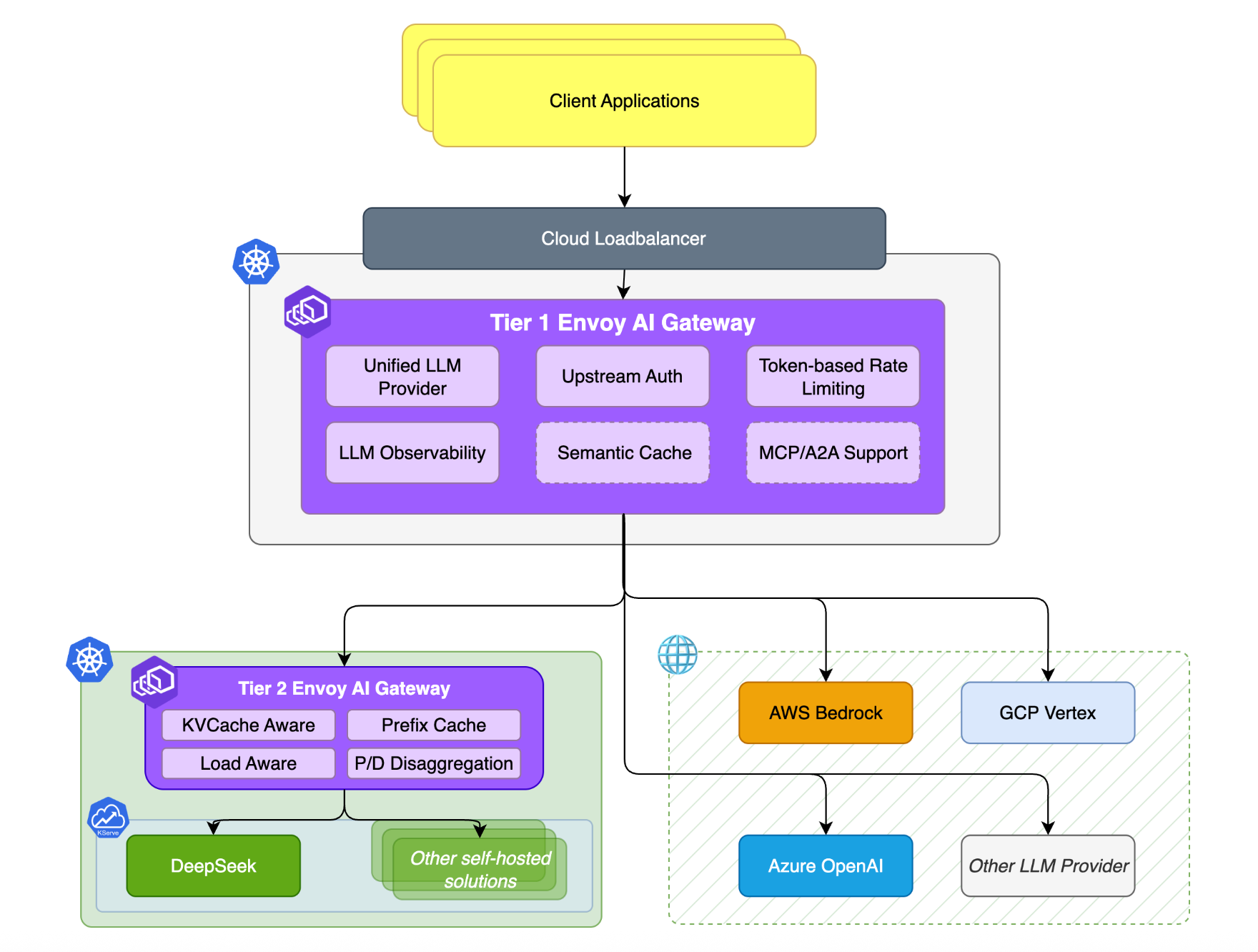
统一模型接入
-
多云/多厂商 LLM:支持接入 OpenAI、AWS Bedrock、Azure OpenAI、Google Vertex AI 等商业服务,以及企业自建开源模型。通过网关,开发者可在不同供应商间平滑切换,按性能或成本择优,实现“一处集成,多处可用”。例如社区项目 OpenRouter 将 OpenAI、Anthropic、Google 等主流模型统一为标准接口(多为 OpenAI API 兼容),并提供单一 API Key 管理入口,便于同时调用多家模型。
-
统一调用接口:为不同模型提供统一调用方式与标准接口,屏蔽底层差异,降低集成成本。开发者仅需使用一种标准 API(如 OpenAI 风格接口)即可调用任意后端模型,无需关心鉴权或请求格式差异。已有应用可无缝切换模型。例如 AWS 的 Bedrock Access Gateway 通过兼容 OpenAI API 的代理,将对 OpenAI API 的调用自动转发至 Bedrock 后端,让应用无需改代码即可访问如 Claude 等模型。该统一化同样适用于 Embedding、语音等接口。
流量治理与可靠性
-
智能路由与负载均衡:可根据请求内容与模型画像选择最合适的模型/实例,并在多实例或多账号间分配负载。例如:简单任务走小模型、复杂任务走大模型,兼顾时延与成本。支持跨供应商的延迟/成本感知调度与多 API Key 均衡,避免单点过载。
-
KV Cache 亲和(KV Cache 指推理过程中的键值对中间状态缓存;前缀缓存 Prefix Caching 指公共前缀的计算结果缓存复用):推理 decode 过程为自回归,KV Cache 存放中间键值以加速连续对话或长序列生成。路由可基于会话标识或前缀缓存将请求导向已具缓存的实例,提高命中率与吞吐。
-
异构设备感知:Kubernetes 集群常包含 A100、H20、H100 等异构 GPU。网关可按硬件性能动态调整权重:高性能 H100 承担更多流量,A100 较少,从而提升整体资源利用率。
-
自动重试与降级:当后端报错、超时或被限流时,自动重试或切换到备用模型,避免业务中断。必要时进行优雅降级,返回部分结果或预设响应,保证连续性与可用性。例如 OpenRouter 的 runner 库支持多模型接入与自动 fallback。
-
弹性限流与配额:支持基于 Token 用量或请求次数的速率限制与配额管理,可针对应用/用户/API Key 设置阈值、突发(Burst)与上限,既防滥用又保护后端稳定。
可观测性与治理
-
用量跟踪:细粒度监控各模型调用次数与 Token 消耗,支持按部门/应用进行费用分摊与预算预测。将成本与性能关联,辅助模型选型与容量规划。
-
日志与审计:记录请求提示词、模型响应、时间、调用者等,形成完整审计链路,便于合规审查、问题定位与提示工程迭代。必要时,这些数据也可为持续优化提供素材。
-
实时监控与报警:监控响应时间、吞吐、错误率等关键指标。可设置阈值(如成功率 < 99% 或平均延迟超标)触发告警,迅速定位故障或瓶颈,保障 SLA。
提示词工程与响应优化
-
Prompt 模板与装饰器:在网关层配置提示词模板,统一输入格式,降低前端拼接错误;通过装饰器在用户 Prompt 前后自动附加系统指令或上下文,实现统一封装与增强,保证输出风格一致并抵御 Prompt 注入。
-
语义缓存:对问答进行向量化存储与相似度检索,命中相似问题时直接返回缓存答案,减少重复调用与时延。在实际场景中可显著降低调用次数与成本,显著提升响应速度。区别于键值缓存,语义缓存理解自然语言相似度,即便换种说法也能命中。
安全与合规
-
敏感信息保护:在请求链路中进行数据防护。对外发提示词进行敏感信息识别、脱敏或拦截;通信采用传输加密(HTTPS)与必要的存储加密,降低隐私泄露风险。
-
提示词防护与规范:对输入启用敏感内容检测与策略校验,阻断违规/恶意请求(如仇恨言论、违法教唆、Prompt 注入 等);对输出集成内容安全审核,发现不当信息立即拦截并返回安全提示,构建输入到输出的合规闭环。
结语
综上,AI Gateway 的出现源于大模型调用在计量方式、流量特性、安全合规与性能要求等方面与传统 API Gateway 的显著差异。通过统一模型接入、智能路由与流量治理、可观测性与用量追踪、**提示词工程与缓存优化安全与合规审查等能力, Gateway 有效应对混合云与多模型环境的复杂挑战。可以预见,AI Gateway 将成为连接大模型与业务场景的关键基础设施,既降低成本与风险,也加速 AI 在产业中的规模化落地。